These tips can help improve the quality of vocals transformed with Vocoflex.
¶ Best Practices
¶ Use Clean/Unprocessed Vocals
For the best results, use clean/unprocessed solo vocals for both the input and target voices in Vocoflex. This means:
- There must be only one person singing/speaking at the same time. No chorus/backing/doubling.
- The vocals are free of reverb, delay, distortion and other effects.
¶ Import Singing Vocals
- Because of the timbre difference between singing and speaking voices, we recommend importing singing vocals to set a target voice, if the input to Vocoflex is also singing vocals.
¶ Import Better Instead of Longer Samples
- 10 seconds of clean solo vocals are enough to set a target voice for Vocoflex.
- Adding more duration to that won’t improve the quality significantly, but on the contrary, may decrease the quality if the longer sample contains heavy processed voices, chorus or instrument sounds.
¶ Insert Effects After Vocoflex, Not Before
- For effects such as equalization, reverb, delay and distortion, always put them after Vocoflex. However, it may be beneficial to add a compressor before Vocoflex if the input has a large dynamic range.
¶ Make Sure the Pitches Match
- Sometimes it could be the differences in the pitch range causing quality degradation on the transformed voice. For example, if the target voice comes from a soprano singing sample while the input is one octave lower, Vocoflex will not be able infer on the voice timbre at the lower voice register.
- Simply click to open the tuner and check if the input aligns well with the imported samples.

¶ Optimize Your Cursor Placement
- Your cursor’s position has a minor but meaningful impact on the overall quality of your processed voices. A voice sample is broken down into small chunks when analyzed by Vocoflex, and the timbre within each chunk (lasting just a few seconds) is represented by a point along the curve. If your cursor is placed too close to any of the points, it will only pick up the timbre from that particular position within the imported sample.
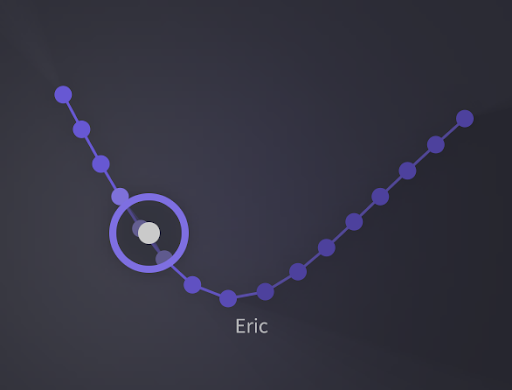
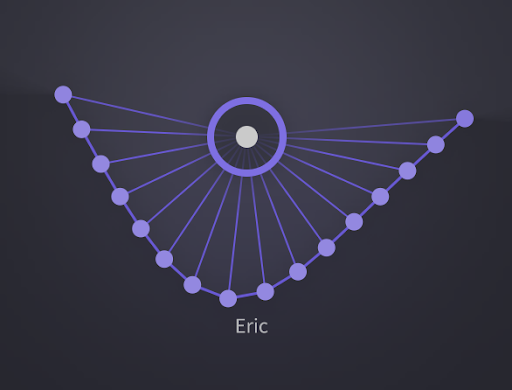
- When used properly, this feature can diversify the expressions. However, unknowingly placing your cursor over some points can lead to a mismatch between the input pitch, and the pitch around that particular position in the voice sample, resulting in a slight quality degradation.